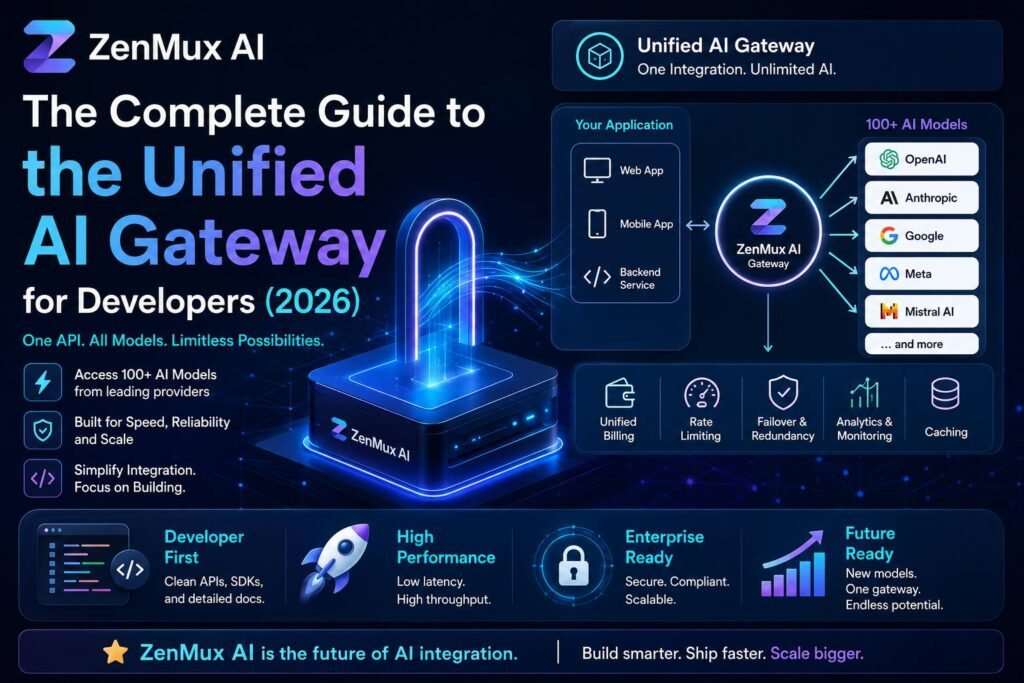
What Is ZenMux AI and Why Developers Are Paying Attention
The AI infrastructure landscape has grown increasingly fragmented. Developers building modern applications now juggle multiple large language model providers, manage conflicting API schemas, and wrestle with rate limits, cost overruns, and reliability gaps — all at the same time. ZenMux AI addresses this problem directly by acting as a unified AI gateway that sits between your application and every major model provider, streamlining access, control, and observability from a single interface.
In this complete guide, we break down everything developers need to know about ZenMux AI in 2026: how it works, what makes it different, and how to integrate it into a production-ready stack.
The Core Problem ZenMux AI Solves
Before diving into features, it helps to understand the pain point. Most teams working with AI in production are simultaneously connected to OpenAI, Anthropic, Google Gemini, Mistral, and a handful of open-source models running on self-hosted infrastructure. Each provider has its own:
- Authentication mechanism
- Rate limiting behavior
- Pricing model
- Response format and error schema
- Latency profile
Managing this complexity manually leads to brittle integrations, duplicated middleware logic, and slow iteration cycles. ZenMux AI abstracts all of this behind a single, consistent API layer, so your application code stays clean regardless of which model is doing the work underneath.
Key Features of the ZenMux AI Gateway
Unified API Interface
ZenMux AI exposes a single RESTful API endpoint that accepts standardized request payloads. Whether you’re routing a request to GPT-4o, Claude 3.5, or a fine-tuned Mistral model, the request structure remains identical on the client side. Response normalization ensures your application always receives data in a predictable format, eliminating the need for provider-specific parsing logic.
Intelligent Request Routing
One of ZenMux AI’s most practical capabilities is its routing engine. Developers can define routing rules based on:
- Cost thresholds — route cheaper, simpler queries to smaller models automatically
- Latency requirements — prioritize providers with the fastest current response times
- Task type — send code generation to one model, summarization to another
- Fallback chains — if the primary provider fails or rate-limits, automatically retry with a secondary
This kind of intelligent routing was previously something teams had to build and maintain themselves. ZenMux AI makes it declarative and manageable through a configuration file or dashboard.
Observability and Usage Analytics
Understanding what your AI layer is actually doing in production is critical. ZenMux AI provides built-in logging, tracing, and analytics that give developers visibility into:
- Token consumption per model and per endpoint
- Request latency broken down by provider
- Error rates and failure patterns
- Cost attribution by team, project, or feature
These metrics are available through a developer dashboard and can be exported to tools like Datadog, Grafana, or any OpenTelemetry-compatible observability stack.
Caching and Cost Reduction
ZenMux AI includes a semantic caching layer that stores responses to similar or identical prompts. When a new request closely matches a cached query, the gateway returns the stored response without hitting the upstream model. For applications with repetitive query patterns — customer support bots, FAQ systems, structured data extraction pipelines — this can reduce API costs by a significant margin.
Security and Access Control
Enterprise teams need more than just routing. ZenMux AI supports role-based access control (RBAC), allowing platform teams to define which services or team members can access which models. API key management is centralized, so rotating credentials or revoking access happens in one place rather than across a dozen provider dashboards.
How to Get Started with ZenMux AI
Getting up and running with ZenMux AI is straightforward for most development environments. The general setup flow looks like this:
- Create an account and configure your provider credentials inside the ZenMux AI dashboard
- Define your routing rules — specify which models to use for which request types and set fallback behavior
- Replace your existing provider SDK calls with the ZenMux AI unified endpoint
- Set up observability by connecting your preferred monitoring tool via the provided integration
Most teams report being able to migrate an existing integration in under a day, particularly if their codebase already abstracts provider calls behind a service layer.
ZenMux AI in a Real-World Architecture
Consider a SaaS product that uses AI for three distinct features: document summarization, code review suggestions, and a conversational support assistant. Without a gateway, each feature is independently wired to its own provider with its own error handling and cost tracking.
With ZenMux AI in place, all three features route through the same gateway. The summarization pipeline might be configured to use a cost-efficient model for short documents and a more capable one for long-form content. Code review routes to a model with strong reasoning capabilities. The support assistant uses a fast, low-latency model with a fallback chain. All of this is managed centrally, and the observability layer shows exactly where money is being spent and where latency spikes are occurring.
Who Should Use ZenMux AI
ZenMux AI is particularly well-suited for:
- Product teams building AI-native features who want to avoid vendor lock-in
- Platform engineers responsible for managing AI infrastructure across multiple internal teams
- Startups that need production-grade AI reliability without building custom middleware
- Enterprises with compliance requirements around data routing and access control
The gateway model scales from a single developer’s side project to a multi-team organization running millions of AI requests per day.
Learn More On CRECSO
Looking Ahead
As model providers continue to multiply and capabilities diverge, the case for a unified AI gateway only grows stronger. ZenMux AI’s approach — standardizing access, enabling intelligent routing, and surfacing actionable observability — reflects where serious AI engineering is heading in 2026. For developers who want to build reliably on top of AI without being consumed by infrastructure complexity, it represents a practical and increasingly essential layer in the modern stack.
READ MORE:
- The AI Entrepreneur Everyone Is Talking About: Suraj Biswas’s Success Story
- What Is SBI Mutual Fund and How Does It Work?
- SBI Mutual Fund: Complete Guide to SIP, Top Funds, Returns, and Investment Options (2026)
Published By Branding.net.in
